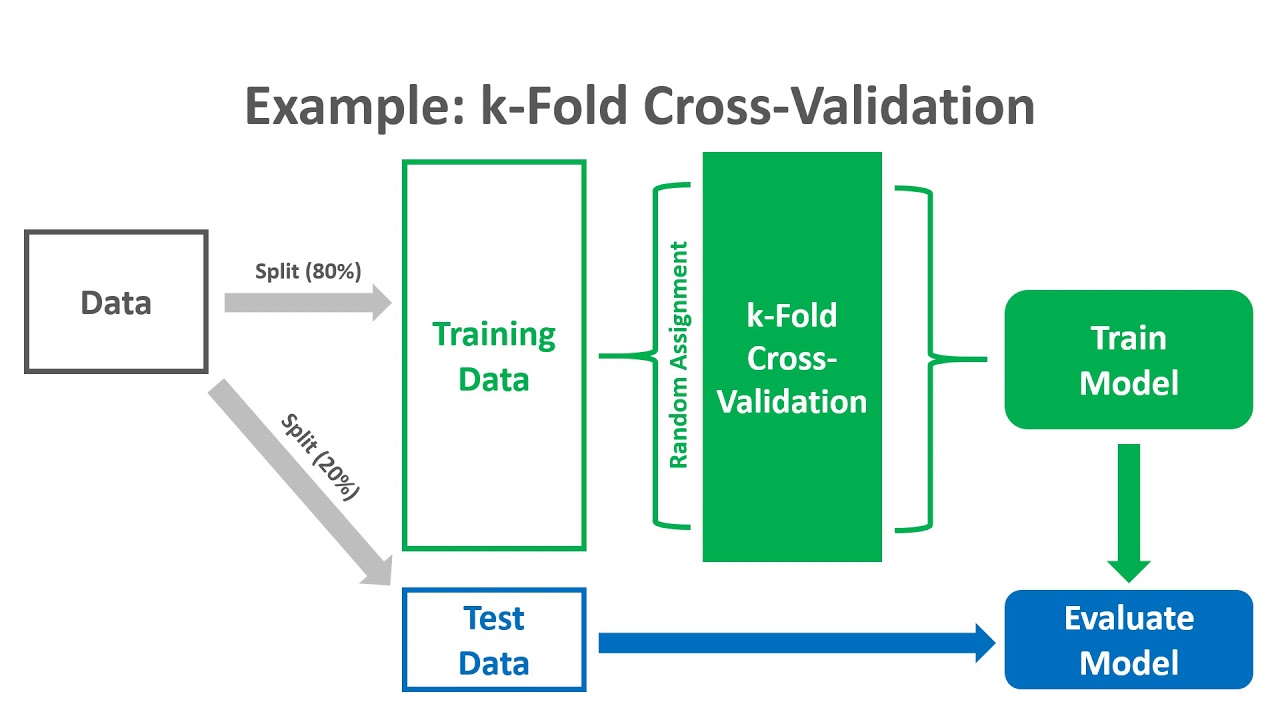
K-Fold Cross Validation / k-fold cross validation in time series with JMP / JMP PRO ... : It is a resampling technique without replacement.. Even though this is not as popular as the validation set approach, it can give us a better insight into our data and model. This parameter decides how many folds the dataset is going to be divided. For i = 1 to i = k. Partition the original training data set into k equal subsets. We would then have a model that is evaluated much more robustly.
Even though this is not as popular as the validation set approach, it can give us a better insight into our data and model. Cross validation solves this problem by dividing the input data into multiple groups instead of just two groups. Let's go back to the original dataset of 1000 samples. What if we could try multiple variations of this train/test split? Partition the original training data set into k equal subsets.
k-Fold Cross-Validation - YouTube from i.ytimg.com Cross validation solves this problem by dividing the input data into multiple groups instead of just two groups. Partition the original training data set into k equal subsets. Split dataset into k consecutive folds (without shuffling). First split the dataset into k groups than take the group as a test data set the remaining groups as a training data set. When we split a dataset into just one training set and one testing set, the test mse calculated on the observations in the testing set can vary greatly depending on which observations. We select k in such a way that k<n and. Here come in the validation and testing parts of the algorithm. The procedure has a single parameter called k that refers to the number of groups that a given data sample is to be split into.
The splitting of data into folds may be governed by criteria such as ensuring that each fold.
This parameter decides how many folds the dataset is going to be divided. Cross validation solves this problem by dividing the input data into multiple groups instead of just two groups. We select k in such a way that k<n and. By using a 'for' loop, we will fit each model using 4 folds for training data and 1 fold for testing data, and then we will call the accuracy_score method from scikit learn to determine the accuracy of the model. Each subset is called a fold. The splitting of data into folds may be governed by criteria such as ensuring that each fold. Even though this is not as popular as the validation set approach, it can give us a better insight into our data and model. First split the dataset into k groups than take the group as a test data set the remaining groups as a training data set. While the validation set approach is working by splitting the dataset once, the. Let's go back to the original dataset of 1000 samples. For i = 1 to i = k. We would then have a model that is evaluated much more robustly. When we split a dataset into just one training set and one testing set, the test mse calculated on the observations in the testing set can vary greatly depending on which observations.
Each subset is called a fold. The procedure has a single parameter called k that refers to the number of groups that a given data sample is to be split into. Provides train/test indices to split data in train test sets. Once the part of the training set is checked to find the best hyperparameter, and the best hyperparameter/s are found, this new data is again sent to the model to be retrained. First split the dataset into k groups than take the group as a test data set the remaining groups as a training data set.
Principle of the k-fold cross-validation | Download ... from www.researchgate.net Now, in this cross validation method, we will take (datasize/k) amount for our testing purpose and the remaining for our training purpose. Even though this is not as popular as the validation set approach, it can give us a better insight into our data and model. There are multiple ways to split the data, in this article we are going to cover k fold and stratified k fold cross validation techniques. The procedure has a single parameter called k that refers to the number of groups that a given data sample is to be split into. Partition the original training data set into k equal subsets. Provides train/test indices to split data in train test sets. It is a resampling technique without replacement. What if we could try multiple variations of this train/test split?
By using a 'for' loop, we will fit each model using 4 folds for training data and 1 fold for testing data, and then we will call the accuracy_score method from scikit learn to determine the accuracy of the model.
Here come in the validation and testing parts of the algorithm. While the validation set approach is working by splitting the dataset once, the. Provides train/test indices to split data in train test sets. There are multiple ways to split the data, in this article we are going to cover k fold and stratified k fold cross validation techniques. We select k in such a way that k<n and. Let's go back to the original dataset of 1000 samples. This parameter decides how many folds the dataset is going to be divided. It is a resampling technique without replacement. The splitting of data into folds may be governed by criteria such as ensuring that each fold. The procedure has a single parameter called k that refers to the number of groups that a given data sample is to be split into. We would then have a model that is evaluated much more robustly. The advantage of this approach is that each example is used for training and validation. For i = 1 to i = k.
The advantage of this approach is that each example is used for training and validation. For i = 1 to i = k. This parameter decides how many folds the dataset is going to be divided. Here come in the validation and testing parts of the algorithm. There are multiple ways to split the data, in this article we are going to cover k fold and stratified k fold cross validation techniques.
k-fold (5-fold) cross validation scheme. In each ... from www.researchgate.net Split dataset into k consecutive folds (without shuffling). When we split a dataset into just one training set and one testing set, the test mse calculated on the observations in the testing set can vary greatly depending on which observations. Each subset is called a fold. The splitting of data into folds may be governed by criteria such as ensuring that each fold. First split the dataset into k groups than take the group as a test data set the remaining groups as a training data set. Now, in this cross validation method, we will take (datasize/k) amount for our testing purpose and the remaining for our training purpose. Let the folds be named as f1, f2, …, fk. Cross validation solves this problem by dividing the input data into multiple groups instead of just two groups.
While the validation set approach is working by splitting the dataset once, the.
While the validation set approach is working by splitting the dataset once, the. Each subset is called a fold. Once the part of the training set is checked to find the best hyperparameter, and the best hyperparameter/s are found, this new data is again sent to the model to be retrained. This parameter decides how many folds the dataset is going to be divided. What if we could try multiple variations of this train/test split? Even though this is not as popular as the validation set approach, it can give us a better insight into our data and model. Let the folds be named as f1, f2, …, fk. By using a 'for' loop, we will fit each model using 4 folds for training data and 1 fold for testing data, and then we will call the accuracy_score method from scikit learn to determine the accuracy of the model. Let's go back to the original dataset of 1000 samples. We select k in such a way that k<n and. When we split a dataset into just one training set and one testing set, the test mse calculated on the observations in the testing set can vary greatly depending on which observations. Split dataset into k consecutive folds (without shuffling). Here come in the validation and testing parts of the algorithm.
Belum ada Komentar untuk "K-Fold Cross Validation / k-fold cross validation in time series with JMP / JMP PRO ... : It is a resampling technique without replacement."


Belum ada Komentar untuk "K-Fold Cross Validation / k-fold cross validation in time series with JMP / JMP PRO ... : It is a resampling technique without replacement."
Posting Komentar